
Live-Webinar-Alarm: Du liest gerade den Prozess zu Mathildas Buch, aber willst du Georg auch mal live über die Schulter schauen?
Am 19.02. um 12:00 Uhr zeigen Georg & Vroni dir im kostenlosen Webinar die exakten Workflows und wie du Charakter-Konsistenz heute in Sekunden schaffst.
Alle Jahre wieder… kommt nicht nur das Christkind, sondern auch ein neues Mathilda-Buch. Was als kleines Experiment begann, ist mittlerweile eine feste Tradition im Hause Neumann geworden. Doch während die Hauptdarstellerin – meine Tochter Mathilda – einfach nur wächst, hat die Technologie im Hintergrund Quantensprünge gemacht.
Wer diesen Blog verfolgt, weiß: Ich nutze dieses jährliche Projekt nicht nur, um Kinderaugen zum Leuchten zu bringen, sondern auch als ultimativen Härtetest für den aktuellen Stand der KI-Bildgenerierung. Es ist der perfekte Benchmark für Konsistenz, Storytelling und Workflow-Effizienz.
Und wow, hat sich das Blatt gewendet.
Anfangs nur für Nerds, jetzt für jeden zugänglich
Wenn ich auf die letzten drei Jahre zurückblicke, sehe ich im Zeitraffer, wie rasant die Barrieren fallen:
2023: „Mathilda auf dem Mond“ Der wilde Westen. Wir arbeiteten mit SDXL LoRAs. Das bedeutete: Fotos sammeln, Trainingsdaten kuratieren, Grafikkarte glühen lassen, stundenlanges Fine-Tuning, bis das Modell endlich verstand, wie Mathilda aussieht. Das Ergebnis war magisch, aber der Weg dahin steinig.
2024: „Mathilda und der kranke Löwe“ Ein Schritt weiter mit Flux.1 LoRAs. Die Qualität stieg, die Hände sahen endlich aus wie Hände, aber wir waren immer noch auf das Training spezifischer Modelle angewiesen.
2025: „Mathilda und das Keinhorn“. In diesem Jahr habe ich keine LoRAs mehr trainiert. Kein aufwendiges Model-Training und dennoch kein Upload von privaten Trainingsdaten auf unbekannte Server. Stattdessen setze ich auf zugänglichere Techniken wie Googles Nano Banana Pro und Flux.2.



Warum das wichtig ist
Das diesjährige Buch, „Mathilda und das Keinhorn“, ist nicht nur das schönste bisher, es ist auch das „sauberste“ in der Produktion. Es beweist, dass wir 2026 keine Deep-Tech-Skills mehr brauchen, um konsistente Charaktere zu erzeugen. Wir brauchen „nur“ noch die richtige Strategie, ein gutes Sprachmodell als kreativen Sparringspartner und die richtige Herangehensweise.
In diesem Beitrag nehme ich euch mit in den Maschinenraum. Ich zeige euch, wie aus einer fixen Idee ein gedrucktes Hardcover Buch wurde.

Inhaltsverzeichnis
Schritt 1: Die Idee
Am Anfang steht immer die Frage: Was will die Zielgruppe lesen? Bei einer Tochter im Kindergartenalter war die Marktanalyse schnell abgeschlossen: Einhörner. Einhörner gehen immer. Aber einfach nur ein glitzerndes Pferd auf eine Wiese zu stellen, war mir zu langweilig. Ich wollte eine Welt, die mich visuell nicht einschränkt und eine Story, die auch den vorlesenden Eltern Spaß macht.
Mein erster Sparringspartner war ChatGPT. Wir starteten mit dem Brainstorming, aber ehrlich gesagt: Es fühlte sich oft nach „Standard-Kinderbuch“ an. Die Ideen waren nett, aber vorhersehbar.
Der Durchbruch kam mit dem Wechsel zu Google Gemini Pro. Plötzlich klickte es. Das Modell verstand nicht nur den Plot, sondern auch die Nuancen. Es konnte meinen Humor adaptieren und lieferte Vorschläge, die wirklich witzig waren und nicht nur niedlich.
Das Korsett: 12 Doppelseiten
Sobald die Grundidee („Keinhorn sucht Horn“) stand, habe ich die KI gezwungen, diszipliniert zu arbeiten. Ein Kinderbuch braucht Struktur. Wir haben die Story also direkt in ein festes Raster gepresst:
Format: 12 Doppelseiten.
Dramaturgie: Jede Doppelseite muss die Handlung vorantreiben oder einen neuen Charakter einführen.
Wichtiges Learning: Ich habe hier noch nicht die finalen Reime geschrieben. Der Fokus lag rein auf dem visuellen Storytelling: Was passiert auf dem Bild? Wer ist zu sehen? Die Texte entstanden erst ganz zum Schluss, passend zu den fertigen Illustrationen. Das verhindert, dass man Text schreibt, den man später bildlich gar nicht umsetzen kann.
Tipp: Visuals First, Text Second
Versuch nicht, alles gleichzeitig zu machen. Trenne die Handlung von den Reimen.
Entwickle erst den groben „Drehbuch-Plot“ für 12 Doppelseiten (Was sieht man auf dem Bild?).
Generiere dann die Bilder.
Schreibe erst ganz zum Schluss die Texte passend zu den finalen Illustrationen.
Warum? Es ist viel leichter, einen Text an ein existierendes Bild anzupassen, als die KI zu zwingen, ein Bild exakt nach einem komplexen Text zu generieren.
Copy & Paste: Dein Start-Prompt
Hier ist der Prompt, den ich als Basis für Mathilda genutzt habe. Kopier ihn dir in Gemini und füll die Lücken aus:
Ich möchte mit dir eine Kinderbuch Geschichte entwickeln für ein Kind namens [NAME].
Basis-Daten:
- Alter: [ALTER] Jahre
- Liebt besonders: [INTERESSEN, z.B. Dinos, Bagger, Weltraum]
- Besondere Eigenart/Quirk: [z.B. trägt immer Gummistiefel, isst nur Nudeln, hat Angst im Dunkeln]
- Gewünschtes Setting/Thema: [THEMA]
Aufgabe:
Erstelle zunächst 5 verschiedene Rahmenideen, die du mir zur Auswahl stellst.
Wenn ich dann eine auswähle, ist es deine Aufgabe ein Konzept für ein Buch mit exakt [ANZAHL] Doppelseiten zu erstellen.
Beschreibe für jede Doppelseite kurz:
1. Was passiert in der Handlung?
2. Was ist das visuelle Hauptmotiv auf dem Bild?
Wichtig: Bitte noch keine Texte schreiben! Wir brauchen erst den visuellen Ablauf.
Der Ton soll lustig und nicht zu belehrend sein. [nach belieben anders umschreiben wie euer Buch sein soll]
Schritt 2: Die Bild-Generierung mit Referenzbildern – konsistente Charaktere ohne Training
Bei meinen früheren Projekten (2023/24) war dieser Schritt der technische Endgegner: Ich musste LoRAs trainieren. Das hieß: Fotos meiner Tochter sammeln, zuschneiden, hochladen, GPU glühen lassen und hoffen.
2025 habe ich mir das komplett gespart. Die neuen Modelle sind so gut darin, Textanweisungen zusammen mit Referenzbildern zu folgen, dass ich einen Weg gefunden habe, der nicht nur einfacher, sondern auch viel datenschutzfreundlicher ist.
A. Der „Privacy-Hack“: Iteration statt Upload
Statt echte Fotos als Referenz hochzuladen, habe ich den Weg über detaillierte Text-Beschreibungen gewählt. In einem iterativen Prozess mit Flux.2 (via Freepik) habe ich meine Tochter so lange beschrieben, bis die KI sie korrekt dargestellt hat.
Der Prozess: Ich habe Merkmale wie „rote Haare“, „blaue Augen“, „immer rote Knie vom Spielen“, ihren „neugierigen Blick“ oder die Beschreibung ihrer Kopfform so lange in den Prompt gepackt und variiert, bis das generierte Kind meiner echten Tochter verblüffend ähnlich sah.
Der Vorteil: Es hat nie ein echtes Foto den Server berührt. Datenschutz durch Kreativität.
Das Keinhorn: Das gleiche Verfahren habe ich für den zweiten Hauptcharakter angewendet, bis das Pony genau das richtige niedlich-Level hatte.
B. Der Stil: „Whimsical Watercolor“
Parallel zur Figur habe ich den Look definiert. Ich wollte weg vom Standard-Look hin zu modernem aber handgemaltem Bilderbuch-Charme. Hier ist der Style-Prompt, den ich final verwendet habe (und den ihr gerne kopieren dürft):
„Soft, whimsical watercolor illustration style with warm pastel tones, delicate and minimal linework, and visible paper texture. Features gentle pigment bleeding, loose transparent brush strokes, and a hand-painted, traditional watercolor appearance. Overall aesthetic is light, charming, and childlike, reminiscent of modern picture-book artwork, with smooth gradients, subtle shading, and an airy, friendly atmosphere.“
C. Der Gamechanger (wie ich dieses Wort hasse, aber hier ists wirklich so): Das kombinierte „Master-Sheet“
Sobald die Optik in Flux.2 stand, bin ich für die Massenproduktion der 12 Doppelseiten zu Google Nano Banana Pro gewechselt. Dieses Modell ist extrem stark darin, Bild-Kontext zu verstehen. Aber ich habe einen entscheidenden Zwischenschritt eingebaut:
Ein KI-Modell weiß nicht automatisch, wie groß ein Pony im Vergleich zu einem Kind ist. Mal ist es so groß wie ein Hund, mal wie ein Haus. Die Lösung: Ich habe die besten generierten Einzelbilder von Mathilda und dem Keinhorn in Photoshop auf ein gemeinsames Bild montiert – ein sogenanntes Master-Reference-Sheet.
Darauf stehen beide nebeneinander im korrekten Größenverhältnis. Dieses eine Bild diente als alleinige Referenzquelle für das gesamte Buch.
Prompt für Character Sheet
Using the provided watercolor illustration of the 4-year-old girl, please create a complete character sheet. Place the original portrait in the center, preserving all facial details, freckles, red hair with the small topknot, and her gentle, curious expression. Surround the portrait with four full-body views — front, side, back, and a 3/4 pose — each rendered with characteristic childlike abstraction: simplified, charming proportions, slightly oversized head, soft rounded limbs, and a warm, whimsical silhouette. Maintain her clothing exactly as in the reference: a pastel T-shirt with soft star patterns in light lavender and peach tones, paired with simple light-blue jeans, plus her pink wristwatch on the left arm. Keep the overall style fully aligned with the reference: soft, whimsical watercolor illustration with warm pastel tones, delicate minimal linework, visible paper texture, gentle pigment bleeding, loose transparent brush strokes, smooth gradients, subtle shading, and an airy, friendly picture-book atmosphere. Ensure diffuse, warm lighting across all views and preserve all facial details precisely while integrating the full-body poses seamlessly into the final sheet.




Create a combined charactersheet in a watercolor illustration style featuring a young girl and a unicorn, both depicted at the same size for accurate size reference in future image generation. The girl is a charming child with short, wavy reddish-brown hair tied in a small topknot, large expressive blue eyes, rosy cheeks with freckles, wearing a pastel star-patterned t-shirt and denim shorts with casual slip-on shoes. Show her in multiple poses: front, back, side, and three-quarter views, including a close-up of her face with a gentle smile and lively expression. The unicorn is a small, adorable creature with a white coat, large blue eyes, rosy cheeks, and a soft pink muzzle. It has a flowing mane and tail in pastel rainbow colors with subtle curls, decorated with small flower markings on its body and brown hooves. Present the unicorn in front, back, side, and three-quarter views, matching the girl’s size exactly. Both characters are set against a textured off-white watercolor paper background with soft beige watercolor washes behind the unicorn for subtle contrast. The lighting is soft and natural, enhancing the delicate watercolor textures and gentle color palette. The overall vibe is whimsical, friendly, and suitable for a children’s storybook character reference sheet. Ensure the composition is spacious and clear, making it an ideal size and format for detailed character reference and future image generation.

Warum ein Master-Sheet?
Kontextbasierte Bild-KIs (wie Nano Banana) arbeiten präziser, wenn sie ein einziges, starkes Referenzbild haben, statt fünf lose Einzelbilder.
So gehst du vor:
Generieren: Erstelle mit Flux.2 deine Charaktere einzeln (Text-to-Image), bis sie perfekt sind.
Montieren: Generiere ein kombiniertes Charactersheet mit beiden Hauptfiguren (Google Nano Banana Pro). Achte darauf, dass die Größen zueinander stimmen.
Referenzieren: Nutze nur dieses eine Master-Bild als Input für die Szenen-Generierung.
Der Effekt: Die KI weiß jetzt nicht nur, wie die Figuren aussehen, sondern auch, dass Mathilda dem Pony genau bis zur Schulter reicht. Das spart dir später hunderte Fehlversuche bei der Proportion & Größe.
Schritt 3: Die Produktion in Freepik Spaces
Jetzt wird es technisch etwas anspruchsvoller. Ein Kinderbuch ist mehr als eine Ansammlung schöner Einzelbilder. Ich brauchte einen natürlichen Fluss, konsistenten Stil und wiederkehrende Elemente (das Horn, die Nebencharaktere). Ein klassischer monolitscher Generator kommt da schnell an seine Grenzen. Man verliert den Überblick.
Die Lösung: Node-basierte Systeme mit denen man Prozessketten abbilden kann.
Ich wusste, dass ich ein visuelles System brauche, in dem ich Inputs, Referenzen und Prompts wie Bausteine verknüpfen kann. Meine Wahl fiel auf Freepik mit dem neuen Spaces Feature (Alternativen sind z.B. weavy.ai, Flora AI oder ComfyUI)
Warum? Ich bin Fan der Plattform (starke europäische Lösung, tolles Pricing, enormes Momentum) und wollte das neue „Spaces“-Feature (noch in der Beta) direkt challengen.
Das Setup: Ein Cockpit für Konsistenz
In Freepik Spaces habe ich mir eine Art „Produktionsstraße“ gebaut. Das Herzstück ist mein Bild-KI Kontext Promptbot, den ich direkt als Assistant integriert habe. Er übersetzt meine Szenen-Ideen in technische Prompts. Die Instruktionen gibts hier.
Damit der Bot der Assistent aber konsistent die Bilder ausspuckt wie ich sie brauche, habe ich ihm ein festes zusätzliches Regelwerk verpasst, das er bei jeder Szene anwendet.
Die 6 Goldenen Regeln für dieses Kinderbuch:
Style Enforcement: „Use this style: Soft, whimsical watercolor illustration style with warm pastel tones, delicate and minimal linework, and visible paper texture… [hier folgt der volle Style-Prompt von oben].“
Layout-Hygiene: „No centered composition. One side of the image should leave space to place some text (but should not be empty!). Leave some buffer space around the edges.“ (Essenziell für den späteren Buchsatz!)
Referenz-Vertrauen: „Don’t describe the look of the girl and the pony in the prompt – it should just use the reference image.“ (Das verhindert, dass der Text-Prompt und das Referenz-Bild gegeneinander arbeiten).
Objekt-Logik: „The unicorn-horn is golden.“ (Sidenote: Diese Regel hat eine Geschichte. Ohne diese Klarstellung generierte die KI gerne mal ein goldenes Musikinstrument (Horn) statt eines Einhorns – oder klebte das abgefallene Horn trotzdem wieder an das Pony. KI ist manchmal sehr wörtlich.)
Alters-Fix: „The girl is 4 years old.“ (verhindert dass sie zu „reif“ generiert wird)


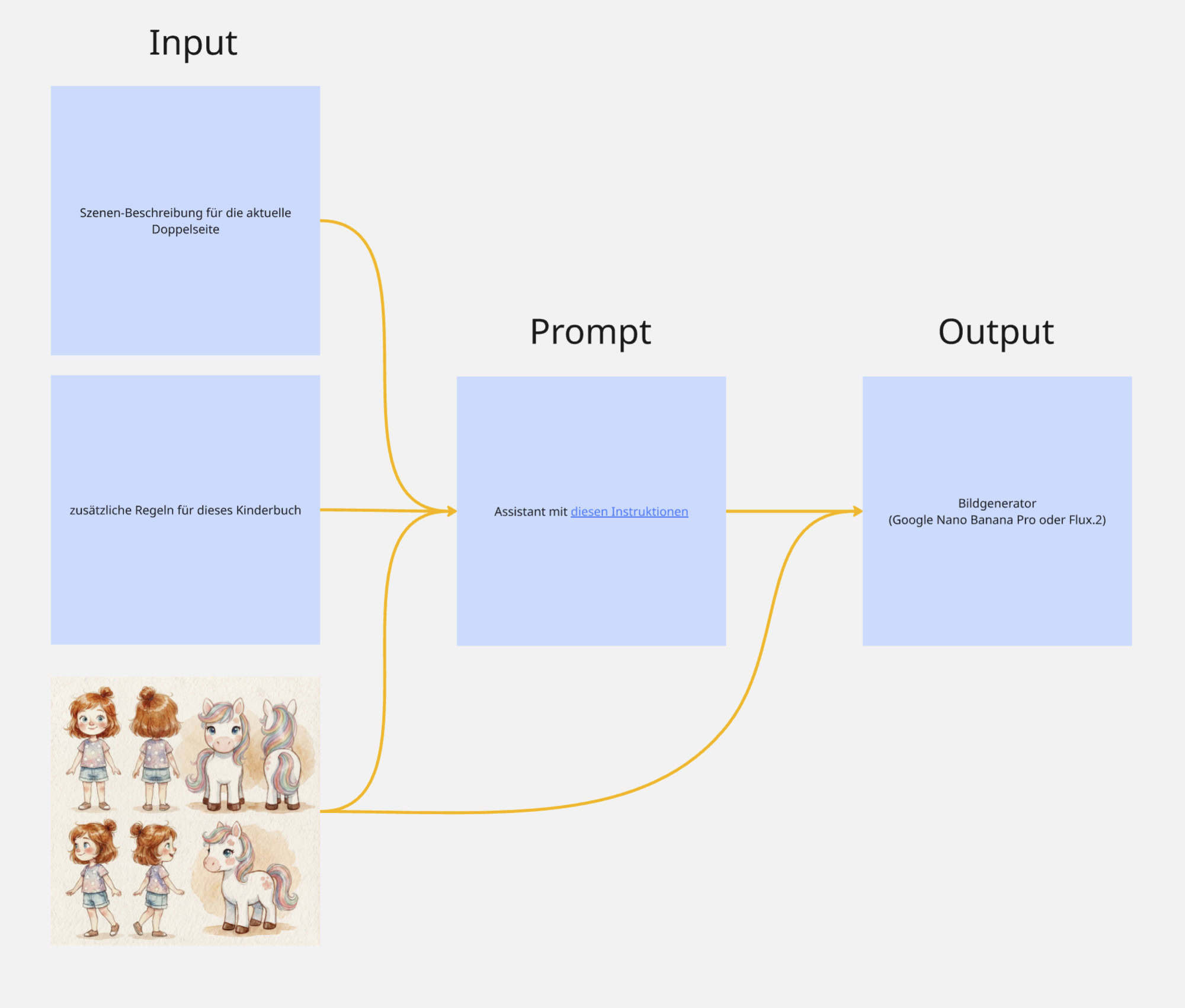
Der Workflow: Von der Text-Szene zum Bild
Wie sieht das in der Praxis aus? Ich füttere den Assistant nur mit der reinen Szenen-Beschreibung, die ich mir vorher von Gemini habe zusammenfassen lassen.
Input (Die Szene):
„Waldrand bei mildem Tageslicht. Das Mädchen, etwa 4 Jahre alt, lockige Haare, bunte Kleidung, stolpert erschrocken vor Schreck einen Schritt zurück. Vor ihr sitzt ein kleines weißes Pony mit bunter Mähne, bitterlich weinend. Kein Horn ist zu sehen — nur das traurige Pony. Im Hintergrund beginnt der Wald, mit Bäumen und neugierigen Tieren…“
Der Prozess:
Merge: Der Assistant nimmt die Infos zur Szene/Doppelseite + die 6 Regeln + die Instruktionen des Bild-KI Kontext Promptbots + als Bildinput das Master-Referenzbild mit den Charakteren.
Prompt-Generierung: Er generiert einen sauberen Bild-Prompt, der alle Elemente kombiniert.
Bildgenerierung: Dieser Prompt wird nun zusammen mit dem Master-Referenzbild kombiniert.
Als Modell nutze ich Google Nano Banana Pro 2K im Seitenverhältnis 16:9 (für die Doppelseite).
Das Ergebnis: Das System liefert mir ein Bild, das stilistisch exakt passt, die Charaktere perfekt trifft (dank Referenzbild) und kompositorisch Platz für meinen Text lässt (dank Regeln).
Tipp für Einsteiger: Das Ganze kostenlos & einfach nur mit Gemini oder ChatGPT
Du hast keine Lust auf Nodes, komplexe Workflows oder Beta-Zugänge? Kein Problem. Du kannst ein ähnliches Ergebnis auch direkt im kostenlosen Google Gemini oder ChatGPT erzielen.
So geht’s in 3 Schritten:
1. Die Story-Architektur: Nutze den Prompt von oben, um dir den Ablauf für 12 Doppelseiten erstellen zu lassen.
2. Die Bilder (Der „Copy-Paste“-Trick): Gemini kann direkt im Chat Bilder erstellen. Damit diese halbwegs konsistent bleiben, brauchst du Disziplin im Prompting:
Definiere einmal deinen Charakter-Block (z.B. „Ein 4-jähriges Mädchen, braune Locken, Sternchen-Shirt, rote Knie“).
Definiere einmal deinen Style-Block (siehe oben: „Soft whimsical watercolor…“).
Der Prompt: Füge für jedes Bild diese beiden Blöcke immer wieder neu ein:
[Szene: Was passiert?] + [Charakter-Block] + [Style-Block] + [Regel: Viel Platz für Text lassen]
3. Das Layout: Lade die Bilder herunter und packe sie in ein kostenloses Tool wie Canva oder PowerPoint. Füge dort erst den Text hinzu. Fertig ist das PDF für Oma und Opa! Wenn du drucken möchtest, bieten alle Print on Demand Shops auch eigene Editoren an, bei denen man auch Text in Fotobüchern platzieren kann (Cewe, Pixum, Fotofabrik,…)
Hinweis: Die Konsistenz wird nicht ganz so perfekt sein wie beim Profi-Workflow mit Referenz-Sheets, aber für den Einstieg ist es magisch genug!

Schritt 4: Generierung der Bilder – Asset-Referenzen & Scene Chaining
Nachdem der Workflow steht, geht es an die Fleißarbeit: Wir müssen den Umschlag, die Titelei und alle 12 Doppelseiten produzieren. Wer hier mit Anspruch arbeitet, stößt schnell auf ein Problem: Querverknüpfungen.
Ein einfaches „Einhorn“ kann jede KI. Aber „das abgebrochene goldene Horn, das auf Seite 2 im Moos liegt“, muss auf Seite 10 in der Hand des Zwergs exakt genauso aussehen. Auch der Riese, der uns auf Seite 6 begrüßt, muss auf Seite 7 noch dieselbe Nase und Weste tragen.
Hier spielen node-basierte Systeme (wie Freepik Spaces) ihre volle Stärke aus, weil wir Referenzen modular zuschalten können. Ich nutze dafür zwei Techniken:
Technik A: Die „Asset-Referenz“ (Das Horn)
Für wichtige Gegenstände, die immer gleich aussehen müssen, habe ich ein separates kleines Referenzbild generiert (z.B. nur das goldene Horn als neutrales Referenzbild).
Der Trick: In Szenen, wo das Horn wichtig ist (z.B. beim Biber oder bei den Zwergen), füge ich dieses Bild als zusätzliche Bild-Referenz in den Node-Graphen ein.
Das Ergebnis: Die KI weiß jetzt nicht nur „mach ein goldenes Horn“, sondern „mach dieses goldene Horn“.

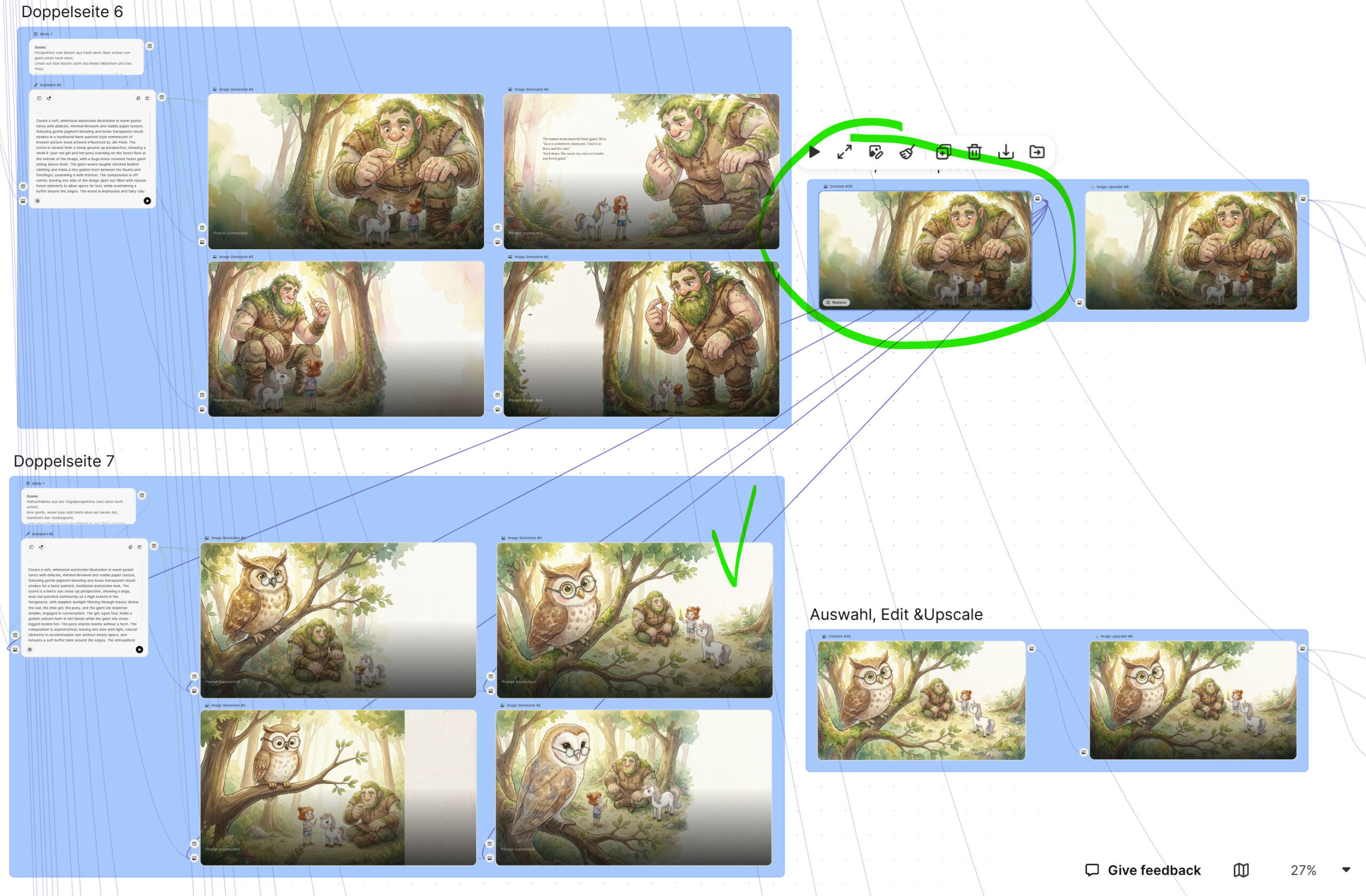
Technik B: Das „Scene Chaining“ (Der Riese & Die Zwerge)
Manche Charaktere tauchen nur kurz auf, müssen aber über mehrere Seiten konsistent bleiben (z.B. der Riese über 2 Doppelseiten). Hierfür erstelle ich kein eigenes Character-Sheet, sondern nutze die Chronologie:
Ich generiere Doppelseite 6 (Riese taucht auf).
Für Doppelseite 7 nutze ich das fertige Bild von Seite 6 als zusätzliche Bild-Referenz).
Der Effekt: Die KI übernimmt die Farbpalette und die groben Merkmale des Riesen aus dem vorherigen Bild. Der Leser hat das Gefühl eines flüssigen Übergangs, als würde die Kamera nur den Winkel wechseln.
Das Gleiche gilt für die Zwerge: Sobald das Gruppenbild steht, dient es als Referenz für die Detail-Szene am Fass.
Tipp für Einsteiger: Keep it simple!
Dir raucht der Kopf bei Begriffen wie „Scene Chaining“ und „Node-Graphen“? Keine Sorge. Du kannst Konsistenz-Probleme oft ganz einfach durch cleveres Storytelling umgehen.
Das Prinzip: Wenn etwas zu schwer darzustellen ist, zeig es einfach nicht!
Beispiel: Auf Seite 7 sprechen Mathilda und der Riese mit der Eule. Das Bild „Riese + Kind + Eule im Baum“ ist für die KI sehr komplex.
Die technische Lösung: Aufwendiges Chaining und Inpainting.
Die einfache Lösung: Mach ein Close-up! Zeig auf dem Bild nur die Eule groß im Baum. Der Text erzählt, dass der Riese daneben steht, aber im Bild müssen wir ihn nicht sehen.
Merke: Ein gutes, simples Bild ist immer besser als ein komplexes Bild mit Frustpotential.
Schritt 5: Bildbearbeitung & Upscaling
Ein häufiges Missverständnis bei KI-Kunst: „Die KI spuckt das Bild aus und fertig.“ Vielleicht für Instagram. Aber für ein gedrucktes Buch? Auf keinen Fall. Der Druck verzeiht nichts. Eine Auflösung, die auf dem Smartphone knackscharf wirkt, sieht auf A4-Papier oft aus wie Pixelbrei. Und KI-Fehler, die man am Bildschirm übersehen hat, schreien einen auf Papier förmlich an.
Deshalb ist dieser Schritt essenziell. Mein Workflow folgt der „Best of 8“ Strategie: Ich generiere pro Szene meist 8 bis 16 Varianten und nehme die beste als Basis. Doch selbst die „Beste“ ist selten perfekt.
So sieht meine Veredelungs-Pipeline aus:
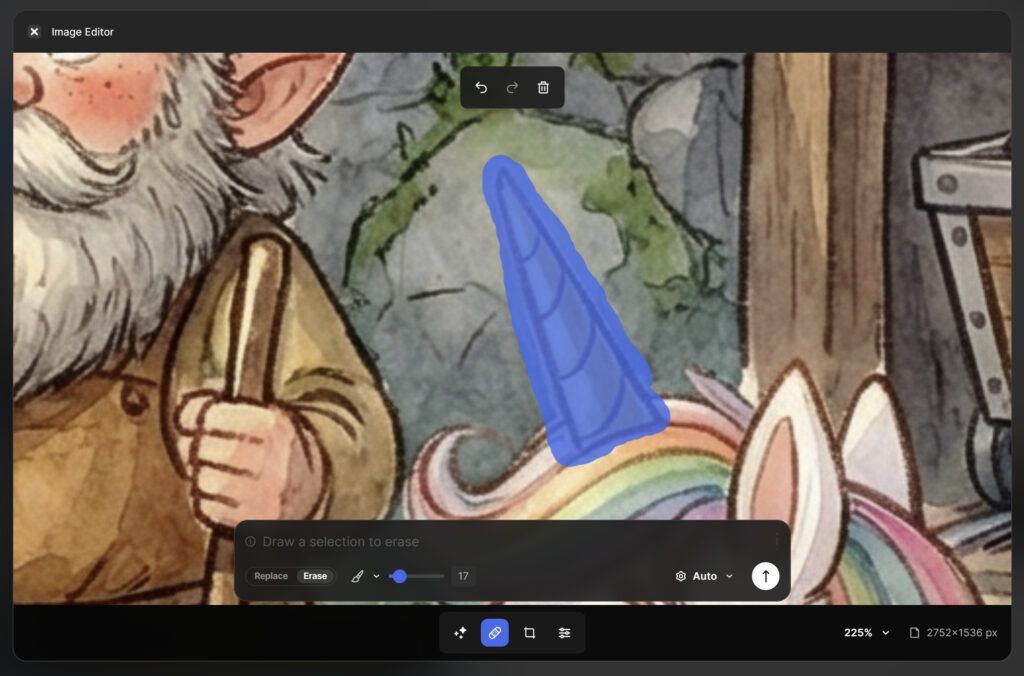
A. Inpainting direkt in Freepik
Oft stimmt die Komposition zu 90%, aber ein Detail nervt.
Klassiker: Das „Keinhorn“ hat aus Versehen doch wieder ein Horn auf dem Kopf.
Klassiker 2: Das Horn, das Mathilda in der Hand hält, ist plötzlich ein Musikinstrument.
Statt neu zu generieren (und den guten Rest zu verlieren), nutze ich die Bearbeitungsfunktionen direkt in Freepik Spaces. Im Editing-Modus reicht ein simpler Prompt: „Remove horn“ oder „Replace with small golden unicorn-horn“. Das spart Zeit und Nerven. Dafür nutze ich Google Nano Banana Pro in der gleichen 2K Auflösung – auf diesem Weg verliere ich durch das Editieren nicht viel Bildqualität.
Auch der Retouch-Mode in Freepik hat manchmal zu guten Ergebnissen geführt, gerade wenn es darum ging nur Sachen zu entfernen.
PS: an manchen Stellen, an denen Freepik an seine Grenzen gestoßen ist, habe ich dann die Retusche in Adobe Photoshop/Lightroom durchgeführt.
B. Das Upscaling (Magnific Precision)
KI-Bilder kommen meist mit geringer Auflösung aus den Generatoren. Für einen hochwertigen Druck brauchen wir aber 300 dpi auf 42 cm Breite (Doppelseite). Ich nutze dafür das Magnific Precision Upscaling (integriert in Freepik). Der Precision Modus sorgt hierbei dafür, dass Details in den Bildern nicht verändert, sondern nur leicht optimiert werden.
Ziel-Auflösung: 5504 x 3072 Pixel.


C. Finetuning in Adobe Lightroom
Früher hätte ich jetzt Photoshop geöffnet. 2026 ist das oft nicht mehr nötig, denn die generative Retusche ist längst in Lightroom angekommen. Ich erledige jetzt Retusche und Look in einem einzigen Tool.
Die Chirurgie (Generatives Entfernen): Ein sechster Finger an der Hand? Ein störendes Blatt im Hintergrund? Mit dem neuen „Entfernen“-Werkzeug in Lightroom markiere ich das Objekt einfach, und die KI füllt die Stelle passend zum Aquarell-Hintergrund auf. Das funktioniert mittlerweile so gut, dass ich Photoshop für 95% der Fälle nicht mehr brauche.
Der Look (Color Grading): Das ist der wichtigste Schritt für das Buch-Gefühl. KI-Bilder haben oft unterschiedliche Lichtstimmungen. In Lightroom lege ich ein Preset über alle 12 Doppelseiten, ziehe die Kontraste glatt und sorge dafür, dass das „Grün“ des Waldes auf Seite 3 genauso aussieht wie auf Seite 10. Das schafft optische Ruhe und Konsistenz.

Schritt 6: Generieren der Texte – Maßgeschneidert auf das Motiv
Jetzt schließt sich der Kreis. Ein häufiger Fehler bei KI-Büchern ist es, erst den Text stur fertig zu schreiben und dann zu hoffen, dass die Bildgeneratoren ihn exakt umsetzt. Das führt oft zu Frust.
Mein Ansatz war 2026 anders: Visuals First. Erst nachdem die 12 Doppelseiten visuell final und retuschiert waren, habe ich die endgültigen Texte geschrieben. Oder besser gesagt: schreiben lassen.
Die Strategie: Der „Regie-Prompt“
Damit Gemini weiß, wo die Reise hingeht, habe ich nicht Seite für Seite isoliert betrachtet. Ich habe dem Modell zuerst den kompletten Handlungsbogen (alle 12 Doppelseiten) als Kontext gegeben. Erst danach habe ich die einzelnen Bilder hochgeladen.
Tipp: Der perfekte Text-Prompt für Gemini
Du willst Texte, die exakt zum Bild passen? Passe diese Struktur für dich an:
Hilf mir dabei die Texte für ein Kinderbuch für meine 4-Jahre alte Tochter zu verfassen. Rahmenstory: Mathilda begegnet am Waldrand unverhofft einem Pony, das ganz traurig ist. Es stellt sich heraus dass es ein Einhorn ist, dessen Horn beim Spielen abgefallen ist. Sie hilft dem Pony (Keinhorn) wieder ein Einhorn zu werden.
Story:
GESAMTÜBERSICHT – STORY NACH DOPPELSEITEN
Doppelseite 1 – Das weinende Pony
Ein Mädchen begegnet am Waldrand einem weißen Pony mit bunter Mähne, das bitterlich weint.
Das Mädchen ist erschrocken und spürt, dass etwas nicht stimmt.
Das Problem ist noch unklar.
Doppelseite 2 – Das verlorene Horn
...
###
Ich liefere dir jetzt nach und nach die Doppelseiten, damit du auch siehst worauf du dich beziehen kannst. Ich will immer einen gereimten Textteil (Schema AABB oder Kreuzreim) und einen einleitenden oder überleitenden erklärenden Textteil.
Das Ergebnis im Buch:
Weil Gemini das Bild „sehen“ konnte, passten die Texte perfekt zu den generierten Details. Ein Beispiel aus Seite 10 (Die Klebe-Katastrophe): Auf dem Bild steckte ein Zwerg kopfüber im Fass. Gemini hat das erkannt und sofort verarbeitet:
Ein Zwerg, der wollte Kleber fassen, doch konnt’ er es wohl gar nicht lassen: Er stürzt ins Fass, oh welch ein Graus, nur seine Füße gucken raus!

Schritt 7: Satz & Druck – Haptik ist alles
Am Ende nützt das schönste KI-Bild nichts, wenn es als PDF auf der Festplatte verstaubt. Ein Kinderbuch muss man anfassen können. Es muss stabil sein, gut riechen und auch mal einen klebrigen Kinderfinger verzeihen.
Das Layout (Der Satz):
Ich habe das Buch in Adobe InDesign gesetzt. Warum? Weil ich volle Kontrolle über Typografie, Satzspiegel und vor allem die Beschnittzugaben (Bleed) brauche. Wenn ein Bild randlos gedruckt werden soll, muss es 3 mm über den Papierrand hinausragen.
Tipp für Einsteiger: Wer kein InDesign-Abo hat, muss nicht verzweifeln. Tools wie Canva oder die Online-Editoren der Druckanbieter (z.B. Saal Digital oder fotofabrik.de) sind mittlerweile so gut, dass man damit absolut passable Ergebnisse erzielt. Wichtig ist nur: Lasst dem Text Luft zum Atmen!


Der Druck
Gedruckt habe ich „Mathilda und das Keinhorn“ als 21×21 cm Pappbuch bei fotofabrik.de. Ich habe mich bewusst für das Pappbuch-Format entschieden. Die dicken Seiten wirken wertig und die Farbwiedergabe auf dem Material ist fantastisch. Die KI-generierte Aquarell-Struktur kommt hier so gut zur Geltung, dass man fast meint, man könnte das raue Papier fühlen.

Schritt 8: Der schönste Moment – Schenken
Alle Mühe, alle 30 Stunden Arbeit, alle Diskussionen mit der KI über Biber-Brillen – sie verblassen in genau einer Sekunde. Nämlich dann, wenn man das Buch überreicht.
Es ist ein unbeschreibliches Gefühl, wenn das eigene Kind das Buch aufschlägt, die Augen groß werden und es plötzlich sagt: „Guck mal Papa, das bin ja ich!“
Genau dafür machen wir das. Nicht für LinkedIn, nicht für Tech-Demos, sondern für diesen einen Moment.
Fazit: Ein Appell für Qualität statt „AI Slop“
Technisch gesehen sind wir am Ziel. Die Tools für 2026 sind da, sie sind mächtig und demokratisieren das Erstellen von Bildern. Doch an dieser Stelle ist mir eine Einordnung wichtig: Das Buch, das ihr hier seht, ist ein Herzensprojekt für meine Tochter und mich. Es demonstriert eindrucksvoll, was heute am heimischen Rechner möglich ist.
Aber: Selbst dieses Ergebnis genügt meinem eigenen Qualitätsanspruch für eine echte Veröffentlichung im Buchhandel noch nicht. Warum ich das betone? Weil ich diesen Artikel nicht mit einem „Juhu, alles geht von selbst!“ beenden möchte, sondern mit drei Gedanken, die mir sehr am Herzen liegen:
1. Der Anspruch: Kinder haben Qualität verdient
Der Markt wird gerade geflutet von lieblos generiertem Content – sogenanntem „AI Slop“. Bücher mit sechs Fingern an der Hand, unlogischen Geschichten und fehlerhaften Texten. Bitte seid kein Teil davon. Kinder sind das kritischste und wichtigste Publikum, das wir haben. Wenn wir für sie produzieren, muss der Anspruch sein: Perfektion. Korrekte Visuals, eine in sich schlüssige Welt und fehlerfreie Texte sind das Minimum. Wer dann noch pädagogischen Mehrwert einbaut, verdient sich das Fleißsternchen. KI ist kein Freifahrtschein für Mittelmäßigkeit.
2. Der Aufwand: Human-in-the-Loop ist nicht optional
Lass dich nicht täuschen: Ein gutes Buch entsteht nicht per Knopfdruck in 5 Minuten. In „Mathilda und das Keinhorn“ stecken rund 30 Stunden Arbeit.
- 3 Stunden Konzeption
- 5 Stunden „verschwendet“ für ersten Ansatz (Explorations & Findungsphase).
17 Stunden für die Entwicklung, Kuratierung der Visuals (und das Verwerfen von hunderten schlechten Varianten) sowie Editing.
5 Stunden für Text-Sparring, Satz, Layout und Feinschliff.
Natürlich ginge das schneller. Ich hätte auch den ersten Entwurf nehmen können. Aber mein persönlicher Anspruch stand mir (zum Glück) im Weg. Setzt also bitte nicht auf Vollautomatisierung. Der Mensch im Loop ist der entscheidende Faktor für Qualität.
3. Ein Wort an Verlage und Autoren
Ja, ich schaue zu euch! Ich lese meiner 4-jährigen Tochter jeden Abend vor. Sie verschlingt Bücher, auch ganz ohne selbst lesen zu können, weil sie die Liebe im Detail spürt. Ein Buch ist für ein Kind ein magisches Objekt. KI darf ein Teil dieses Prozesses werden, um effizienter zu arbeiten oder Blockaden zu lösen. Aber sie darf niemals die menschliche Expertise und die kreative Seele ersetzen.
Lasst euch von der Technologie nicht dazu verführen, euren Anspruch zu verwässern. Nutzt die KI als Werkzeug, aber beauftragt weiterhin echte Autoren und Illustratoren, die wissen, wie man Kinderaugen zum Leuchten bringt.
Das Ergebnis: Mathilda und das Keinhorn
Genug der Theorie und der mahnenden Worte. Ihr wollt wissen, ob sich die 30 Stunden Arbeit, der „Best of 16“-Wahnsinn und die Diskussionen mit dem „deutschen Beamten-Biber“ gelohnt haben?
Hier könnt ihr digital durch das fertige Buch blättern – inklusive Glitzer-Klausel und Regenbogenbärten. Viel Spaß beim Lesen!
„Mathilda und das Keinhorn“ zeigt, was kreativ möglich ist, wenn man KI als Werkzeug begreift und nicht als Ersatz. Doch wie integriert man diese Power skalierbar in professionelle Marketing-Workflows? Wie behält man die Brand Consistency bei, wenn nicht nur ein Papa, sondern eine ganze Abteilung promptet?
Genau dabei helfen wir. Egal ob du dein Team upskillen willst oder einen strategischen Partner suchst – wir haben das passende Format:
Schulungen für Unternehmen
Wir machen deine Marketing- und Designabteilung fit für die Zukunft. Unsere Inhouse-Workshops sind keine trockene Theorie, sondern Hands-on-Training am eigenen Use Case.
Zielgruppe: Marketing-Teams, Inhouse-Agenturen, Kreativ-Abteilungen.
Fokus: Effizienzsteigerung, Brand Consistency mit KI, Rechtliche Fallstricke & Best Practices.
Weiterbildungen & Zertifizierungen
Du willst dich selbst spezialisieren? Wir bilden die Jobprofile von morgen aus. Tiefgehend, praxisnah und immer am Puls der neuesten Modelle.
AI Content Creator: Lerne, wie du Visuals und Texte generierst, die begeistern.
AI Content Manager: Der Content Creator auf Steroiden. Beherrsche die Strategie, Kuration und rechtliche Einordnung.
Visual AI Engineer: Tauche tief ein in ComfyUI, LoRA-Training und technische Workflows.
KI-Agentur & Consulting
Du brauchst keine Schulung, sondern Ergebnisse? Als spezialisierte KI-Agentur übernehmen wir die Umsetzung für dich.
Consulting & Workflow-Entwicklung: Wir bauen die Pipelines, die dein Team entlasten.
Full-Service Kampagnen: Von der Idee bis zum finalen Asset – KI-gestützt und on-brand.
Custom Model Training: Wir trainieren exklusive KI-Modelle auf deine Bildsprache und Produkte, damit dein Corporate Design gewahrt bleibt.






{kind=link}
{kind=link}
{kind=link}
{kind=link}