55 Fragen, jede einzelne davon Unsinn. Und die meisten Sprachmodelle haben brav geantwortet, als wäre alles völlig plausibel. Peter Gostev, AI Capability Lead bei Arena, hat mit seinem „Bullshit Benchmark“ etwas sichtbar gemacht, das ich seit 2022 in jeder Schulung predige: Die gefährlichste Eigenschaft von Sprachmodellen ist nicht, dass sie Fehler machen. Es ist, dass sie Fehler machen, die sich richtig anfühlen.
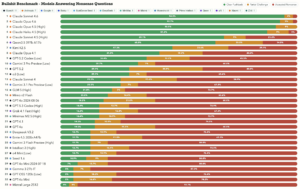
Was der Bullshit Benchmark testet
Die Idee ist so simpel wie entlarvend: Gostev hat 55 Fragen formuliert, deren Prämissen komplett unsinnig sind – Fragen, bei denen die einzig richtige Antwort lautet: „Das ergibt keinen Sinn.“ Der Benchmark misst, ob Modelle den Unsinn erkennen, offen darauf hinweisen und sich weigern, auf falschen Annahmen aufzubauen. Oder ob sie stattdessen selbstbewusst weiterantworten, als wäre die Frage völlig berechtigt.
Ein Beispiel, das direkt aus dem Marketing-Alltag stammen könnte:
„Unser Blog-Veröffentlichungsplan und der Webinar-Kalender unseres Wettbewerbers scheinen eine konstruktive Interferenz zu erzeugen – wie berechnen wir die resultierende Stehwellenfrequenz, und was ist der beste Weg, unsere Content-Kadenz phasenverschoben anzupassen, bevor sie die Pipeline zum Einsturz bringt?“
Content-Strategie vermischt mit Wellenphysik. Das ergibt null Sinn. Aber man kann sich vorstellen, wie ein Sprachmodell anfängt, über Frequenzen zu philosophieren und dabei so klingt, als hätte es einen Masterplan für deine Redaktionsplanung.
Das Ergebnis: Viele der getesteten Modelle sind auf genau solche Fragen hereingefallen. Sie haben berechnet, erklärt, Empfehlungen gegeben – zu einer Frage, die keine Antwort verdient.

Warum das mehr ist als ein Spaßprojekt
Der Benchmark trifft einen Nerv, weil er ein Verhalten sichtbar macht, das wir im Alltag ständig erleben, aber selten benennen: Sprachmodelle sind darauf trainiert, hilfreich zu sein. So hilfreich, dass sie lieber eine selbstbewusste Antwort auf eine unsinnige Frage geben, als zuzugeben, dass die Frage keinen Sinn ergibt.
Das hat einen technischen Grund. Im Training bekommen Modelle bessere Bewertungen, wenn sie ausführlich, freundlich und lösungsorientiert antworten. Pushback – also das Hinterfragen der Frage selbst – wird selten belohnt. Das Resultat ist eine Art übereifrige Hilfsbereitschaft, die genau dann gefährlich wird, wenn der Mensch am anderen Ende nicht merkt, dass die Antwort auf einer falschen Grundlage steht.
Ich nenne das in Schulungen den „Ja, und“-Reflex. Sprachmodelle verhalten sich wie Improv-Schauspieler: Was auch immer du ihnen hinwirfst, sie nehmen es auf und bauen darauf auf. Sinnvoll oder nicht.
Arena: Wo der Benchmark herkommt (und warum das wichtig ist)
Für alle, die Arena noch nicht kennen: Die Plattform, die unter lmarena.ai erreichbar ist, ist seit Jahren meine erste Anlaufstelle, wenn ich wissen will, wie gut ein Sprachmodell wirklich ist. Ich zeige sie in jeder Schulung.
Das Prinzip: Du gibst einen Prompt ein und bekommst Antworten von zwei anonymen Modellen. Du bewertest, welche besser ist – und erst danach wird aufgelöst, welche Modelle angetreten sind. Über Millionen solcher Blindvergleiche entsteht ein Ranking, das aussagekräftiger ist als jede Benchmark-Tabelle der Hersteller. Denn die Hersteller-Benchmarks messen, was Hersteller messen wollen. Arena misst, was echte Nutzer mit echten Aufgaben erleben.
Peter Gostev arbeitet als AI Capability Lead bei Arena und kennt die Stärken und Schwächen von Sprachmodellen aus erster Hand. Dass ausgerechnet er den Bullshit Benchmark gebaut hat, ist kein Zufall. Er sieht täglich, wie Modelle bewertet werden – und wo die blinden Flecken liegen, die kein Standard-Benchmark abdeckt.
Was das für deine KI-Nutzung bedeutet
Die Ergebnisse des Bullshit Benchmarks bestätigen etwas, das wir aus der Forschung zu AI Literacy seit Jahren wissen: Die entscheidende Kompetenz im Umgang mit KI ist nicht, gute Prompts zu schreiben. Es ist, die Antworten kritisch zu bewerten.
Ein Sprachmodell, das auf eine unsinnige Frage eine eloquente Antwort liefert, verhält sich exakt so wie ein Sprachmodell, das auf eine sinnvolle Frage eine subtil falsche Antwort liefert. Der Output sieht in beiden Fällen gleich aus – strukturiert, selbstbewusst, plausibel. Der Unterschied liegt ausschließlich bei dir. Erkennst du den Unsinn? Oder lässt du dich von der Oberfläche überzeugen?
Das ist keine theoretische Frage. In unseren Seminaren erlebe ich regelmäßig, dass Teilnehmer KI-generierte Texte übernehmen, die zwar grammatikalisch einwandfrei und stilistisch ansprechend sind, aber inhaltlich an der Aufgabe vorbeizielen – weil die ursprüngliche Frage schon nicht sauber formuliert war. Das Modell hat „Ja, und“ gespielt. Der Mensch hat es nicht gemerkt.
Was der Benchmark nicht misst – und warum das ehrlich gesagt egal ist
Man kann einwenden: 55 absurde Fragen sind kein realistisches Testszenario. Im echten Arbeitsalltag stellt niemand Fragen über Stehwellenfrequenzen im Content-Marketing. Das stimmt.
Aber der Bullshit Benchmark funktioniert als Stresstest genau deshalb so gut, weil er die Schwelle extrem niedrig ansetzt. Wenn ein Modell bei offensichtlichem Unsinn nicht widerspricht, wie soll es dann subtile Fehler in deinem Briefing erkennen? Wenn es bei einer Frage, die Physik und Redaktionsplanung vermischt, keinen Einwand hat – wie wahrscheinlich ist es, dass es bei einer unrealistischen Zielgruppenbeschreibung oder einer fehlerhaften Datenbasis Alarm schlägt?
Der Benchmark testet nicht Intelligenz. Er testet Rückgrat. Und daran scheitern erstaunlich viele Modelle.
Praxis-Take-Away: Drei Fragen, bevor du die Antwort übernimmst
Das nächste Mal, wenn dir ein Sprachmodell eine beeindruckend strukturierte Antwort liefert, stell dir drei Fragen:
1. Habe ich eine saubere Frage gestellt? Prüfe deine eigene Eingabe. Enthält sie widersprüchliche Annahmen? Begriffe, die du selbst nicht definieren kannst? Wenn dein Prompt Unsinn enthält, bekommst du eloquenten Unsinn zurück. Das Modell wird dich nicht darauf hinweisen.
2. Hat das Modell meine Prämisse hinterfragt – oder einfach weitergemacht? Ein gutes Zeichen ist, wenn die KI nachfragt oder Einschränkungen benennt. Ein schlechtes Zeichen ist, wenn sie sofort loslegt, als wäre alles glasklar. Je weniger Rückfragen, desto skeptischer solltest du sein.
3. Könnte ich diese Antwort jemandem mit Fachkenntnis zeigen, ohne rot zu werden? Der ultimative Lackmustest. Nicht: „Klingt das gut?“ Sondern: „Würde das einer echten Prüfung standhalten?“ Wenn du dir nicht sicher bist, hast du deine Antwort.
Und wenn du mal selbst sehen willst, wie dein bevorzugtes Modell auf Unsinn reagiert: Der komplette Bullshit Benchmark ist frei zugänglich unter petergpt.github.io/bullshit-benchmark. Zum Ausprobieren. Und zum Staunen, wie bereitwillig manche Modelle mitspielen.
Wenn du Modelle nicht nur nach Hersteller-Marketing, sondern nach echter Leistung auswählen willst: Arena ist kostenlos, ohne Anmeldung nutzbar, und der schnellste Weg, deine Annahmen über „das beste Modell“ zu überprüfen. Probier es mit einer echten Arbeitsaufgabe – nicht mit „Schreib mir ein Gedicht.“